A digital brain, as coined by Andrej Karpathy, is a personal knowledge infrastructure built from documents the researcher trusts. It generates answers with references back to the underlying material. This guide documents a pipeline for building one from any corpus. It adapts Karpathy’s methodology and adds six research-specific contributions that turn the system from a retrieval tool into a hypothesis-generation instrument.
1. Introduction
Every (competition) lawyer has the same problem. The European Commission has issued hundreds of decisions over the past forty years. No one has read them all. No one remembers the ones they have read in enough detail to spot when a new case contradicts an old one.
I built a digital brain that addresses this. I fed it all 508 European Commission competition decisions from 1977 to 2025. I can now query the entire corpus in plain English and get answers grounded in the actual decisions, with citations. The results are striking. Which decisions the Commission’s own case law treats as foundational. Which theories of harm were articulated once and never developed. Where Apple Mobile Payments quietly reshapes market definition through an after-markets analogy. How ecosystem reasoning has crept into digital cases without ever becoming a unified theory.
The way I see it, every law firm should build one. Every competition agency should also build one. A draft decision can be checked against the full decisional record before it is issued. A brief can be tested against every prior ruling on the same theory. Inconsistencies then appear before they reach appeal rather than after. The same problem confronts researchers. A scholar at the frontier of any field has read hundreds of papers and cited many of them. Reading and citing are not the same as retaining the argument. By the time a researcher writes, the connections between sources that seemed clear during reading have often faded. A paper read a decade ago survives in memory as a conclusion at best, rarely as an argument.
The knowledge graph addresses this directly. It externalizes the structure of the literature. It makes connections visible and queryable at the moment of writing rather than relying on memory. The pipeline described here takes a folder of PDF files and produces three outputs. The first is a clean Markdown version of every document. The second is a knowledge graph that extracts concepts and reasoning patterns from across the corpus and maps them into a queryable structure. The third is a wiki, a set of Wikipedia-style articles organized by thematic cluster, with cross-links between related topics and a master index. Once the graph is built, the researcher can query it in natural language. Every answer is grounded in the source documents and traceable to a specific page.
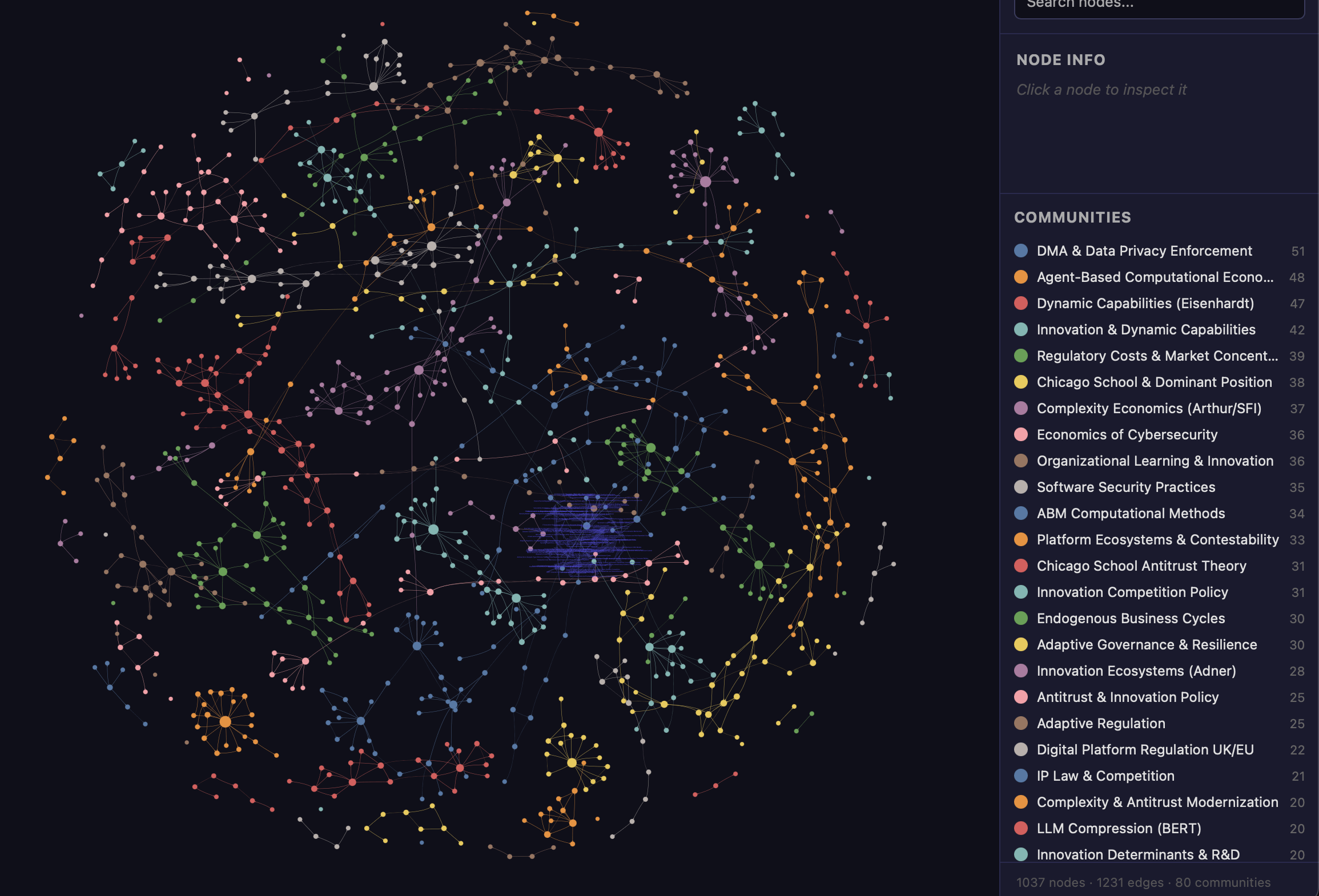
2. The Pipeline in Five Steps
The pipeline has five steps plus ongoing maintenance. Each step feeds into the next. The process can be interrupted and resumed at any point.
- Step 1 is collection. Gather source documents as PDF files and organize them into thematic subfolders.
- Step 2 is conversion. Convert all PDFs to Markdown using MarkItDown, a Python utility developed by Microsoft. The conversion runs in parallel.
- Step 3 builds the knowledge graph with Graphify, an AI coding skill developed by Safi Shamsi. Graphify dispatches parallel AI agents that extract concepts and relationships from every document and merge the results into a single graph.
- Step 4 generates the wiki. Each thematic cluster in the graph becomes a wiki article, with source summaries and cross-links to related topics.
- Step 5 is querying. The researcher asks questions of the corpus through an AI assistant. Structured graph commands trace paths between specific nodes or surface clusters of related decisions.
Maintenance is incremental. New documents are dropped into the relevant folder, and the pipeline re-runs. Graphify’s SHA-256 cache ensures that only new or changed files are re-processed. The existing graph is not rebuilt from scratch. A standard laptop is sufficient to run the pipeline. No dedicated graphics processor is required.
3. Schema Design for Research
The original Graphify methodology was developed for software engineering and personal knowledge management. Used without modification, it produces a retrieval system. Used deliberately for research, it requires a schema design step that the Graphify documentation does not specify. The schema lives in a file called CLAUDE.md, placed in the root folder. Everything inside it becomes part of the AI’s working context during extraction. Four design choices differentiate a research schema from a minimal one.
Authority weighting encodes document hierarchy. A corpus mixing scholarship, administrative decisions, and appellate judgments requires three tiers. The weighting prevents the AI from treating a student note and a Court of Justice judgment as equivalent sources. Absence as a query target instructs the AI to flag what the sources do not address, not only what they say. The graph surfaces connected components automatically, but explicit instructions amplify this. Every wiki article ends with a section titled “What the sources do not address.” Conceptual anchors encode the field’s core terms as priority nodes. For antitrust research, concepts like market definition, theory of harm, and efficiency defense appear explicitly. The AI extracts these first, which changes the community structure of the resulting graph. Claim-level extraction moves the unit of analysis from documents to propositions. Two papers that look connected at the document level often defend incompatible claims at the propositional level. An absent path between two claims carries different meaning than an absent path between two documents. The schema is the only instrument through which a researcher can shape the graph before it is built. Used carefully, it determines whether the resulting system retrieves information or generates hypotheses.
4. A Six-Step Query Protocol
Retrieval is a starting point rather than an end point for research. The protocol below specifies how to query a completed graph to generate hypotheses. The six steps run in sequence on any completed corpus.
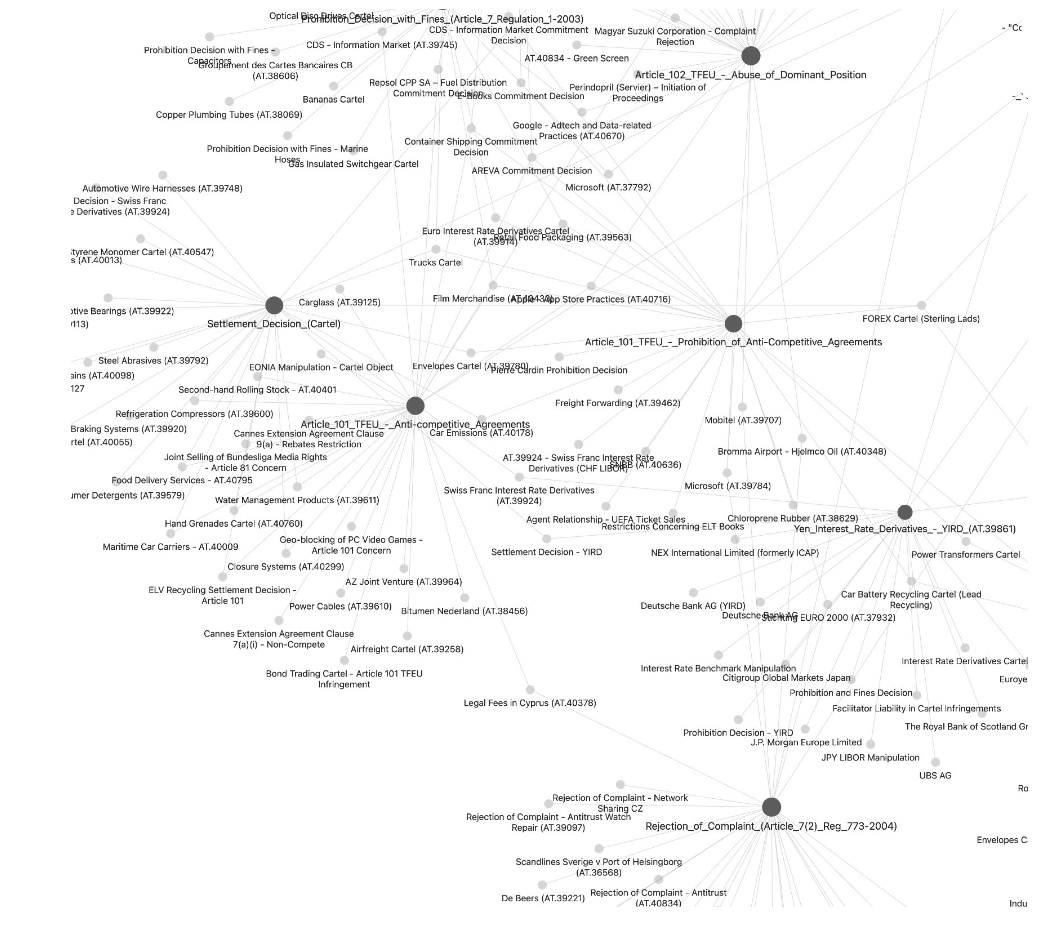
- Step 1 identifies the god nodes. These are the highest-degree concepts in the graph, the ideas to which the largest number of other nodes connect. They reveal what the field treats as foundational. A corpus in which Gundlach and Foer (2006) is the most-connected node has organized itself around a particular conception of the relationship between complexity, networks, and antitrust. A corpus in which Intel (AT.37990) is the most-connected node is a decisional corpus organized around a particular theory of exclusionary conduct.
- Step 2 identifies disconnected components. The graph will almost always contain clusters with no extracted connections to the main body of the corpus. These are the field’s frontiers and its dead ends. A disconnected cluster may represent an emerging subfield that has not yet been cited into the mainstream, or a line of argument that was tried and abandoned.
- Step 3 queries for absent paths. The researcher asks the graph for paths between pairs of nodes that should, on theoretical grounds, be connected but are not. The absence of a path is a finding. It means the literature has not yet made a connection that theory suggests should exist. The research corpus documented here returned no path between the Collingridge Dilemma and Arthur’s technology lock-in theory. That is a paper potentially waiting to be written.
- Step 4 compares two graphs built on different corpora covering the same domain. A scholarly literature graph and a regulatory decisions graph will typically contain different god nodes and different connections. Concepts densely connected in the scholarly graph but absent in the regulatory graph are candidates for regulatory adoption. Concepts prominent in regulatory decisions but untheorized in scholarship are candidates for academic work.
- Step 5 is an authority-chain conflict check for legal corpora. The researcher queries for nodes where scholarship and court judgments state contradictory positions. A concept that scholarship addresses one way but a court resolves differently is a site of doctrinal evolution.
- Step 6 is a health check. The researcher queries for concepts mentioned across the corpus but never explained. These are nodes with many incoming edges and no outgoing edges, the field’s assumed knowledge. In legal and regulatory research, these often correspond to foundational concepts whose content is contested precisely because no one has defined them carefully.
The protocol is organized around the principle that in mature research fields, the most useful finding is a gap. Content retrieval is readily available through conventional search. A structural map of what the corpus does not say is not.
5. The Hypothesis Register
The six-step protocol produces a set of hypotheses each time it runs. An absent path is a conjecture. A god node is a structural claim about the field. A disconnected cluster is a prediction that a body of work has not been integrated. The register stores each as a dated entry in hypotheses.md. Every entry records the generating query, the graph state at the time, and the evidence the query returned. When the corpus is updated, the register re-runs each stored query against the new graph. The result is appended to the original entry with a new date. The register accumulates into a research diary. A hypothesis that held in April 2026 and failed in April 2027 is a documented shift in the field. A hypothesis that held across two years of new material is a proposition the field has not contradicted. Both outcomes are research findings.
6. Complexity-Theoretic Diagnostics
The knowledge graph is a network. Networks can be measured against the benchmarks that network science has established. The diagnostic module runs after each graph build and writes its results into GRAPH_REPORT.md. The degree distribution tells the researcher whether the graph is scale-free. A scale-free graph has a small number of god nodes that accumulate a disproportionate share of the connections and a long tail of nodes with few connections each. Most mature scholarly fields are scale-free. A corpus that produces a flat degree distribution is one whose attention has not found its centers, which usually means the extraction has missed them.
The clustering coefficient together with the mean path length tells the researcher whether the graph is small-world. A small-world graph is one in which most nodes can be reached from any other in a few steps and in which connections cluster locally. A graph that fails the small-world test has subcommunities that are barely linked, and the failure is itself a finding. The entropy across communities measures whether attention is concentrated or diffuse. A field organized around a small number of dominant frames has low community entropy. A field in broad exploration has high entropy. The trend of this metric across successive graph builds reveals whether the field is consolidating or expanding.
When more than one graph is available, the diagnostics run pairwise. A scholarly graph and a regulatory graph on the same domain will typically diverge on these metrics. Each divergence is a diagnostic signal about the gap between the two institutional perspectives on the problem.
7. Applications
An administrative agency drafting a new decision can drop the draft into a brain built from all previous decisions and query it for consistency. The system surfaces prior decisions that address the same legal standard or the same theory of harm. Inconsistencies become visible before the decision is issued rather than on appeal. The same applies to courts. A draft judgment can be checked against a corpus of prior rulings. Lawyers can check a brief against a corpus of decisions for doctrinal consistency. An economic theory can be tested against the literature before submission. A paper read ten years ago survives in memory as a conclusion. In the brain, it survives as an argument with traceable connections.
Three deployment configurations are available. A single researcher maintains a private brain. A team shares a folder where collaborators deposit new sources. An institution publishes a queryable version of its own decisional or scholarly corpus, allowing anyone to query it in natural language without technical knowledge of the underlying structure. The EU digital regulatory framework illustrates a fourth application. As of 2024, eight major regulations govern the digital economy, from the Data Governance Act to the Cyber Resilience Act. They were adopted over a three-year window by different legislative teams responding to different problems. They define the same concepts differently and impose overlapping obligations on the same regulated entities. Structural gaps become visible only when the texts are read together. No single person has read all eight with sufficient attention to map every overlap. A knowledge graph built from these regulations makes the structure visible. It identifies every provision that uses the term “AI system” and compares the definitions in force across acts. It traces which regulated entities are subject to obligations under multiple acts simultaneously.

8. What the Pipeline Adds
Karpathy’s methodology, implemented through Graphify and MarkItDown, produces a queryable knowledge base. The six contributions described here turn that knowledge base into a research instrument. Schema design shapes the graph before it is built. The query protocol mines it for findings once it is built. The hypothesis register preserves those findings and re-tests them as the corpus grows. The diagnostic module measures the graph’s own network properties and reports what they imply for the field.
The pipeline is field-neutral. The two implementations documented in the full version of this guide, one academic research corpus and one European Commission decisions dataset, are illustrative examples. Every discipline will generate its own applications once the system is built.
Forthcoming in the Network Law Review, Spring 2026. The full version of the guide, with installation commands, code, and the complete EC implementation, is available on SSRN.